Reddit热议!DeepSWE排名引发AI编程模型大讨论
2026-06-01 02:59:49
72次阅读
2个评论
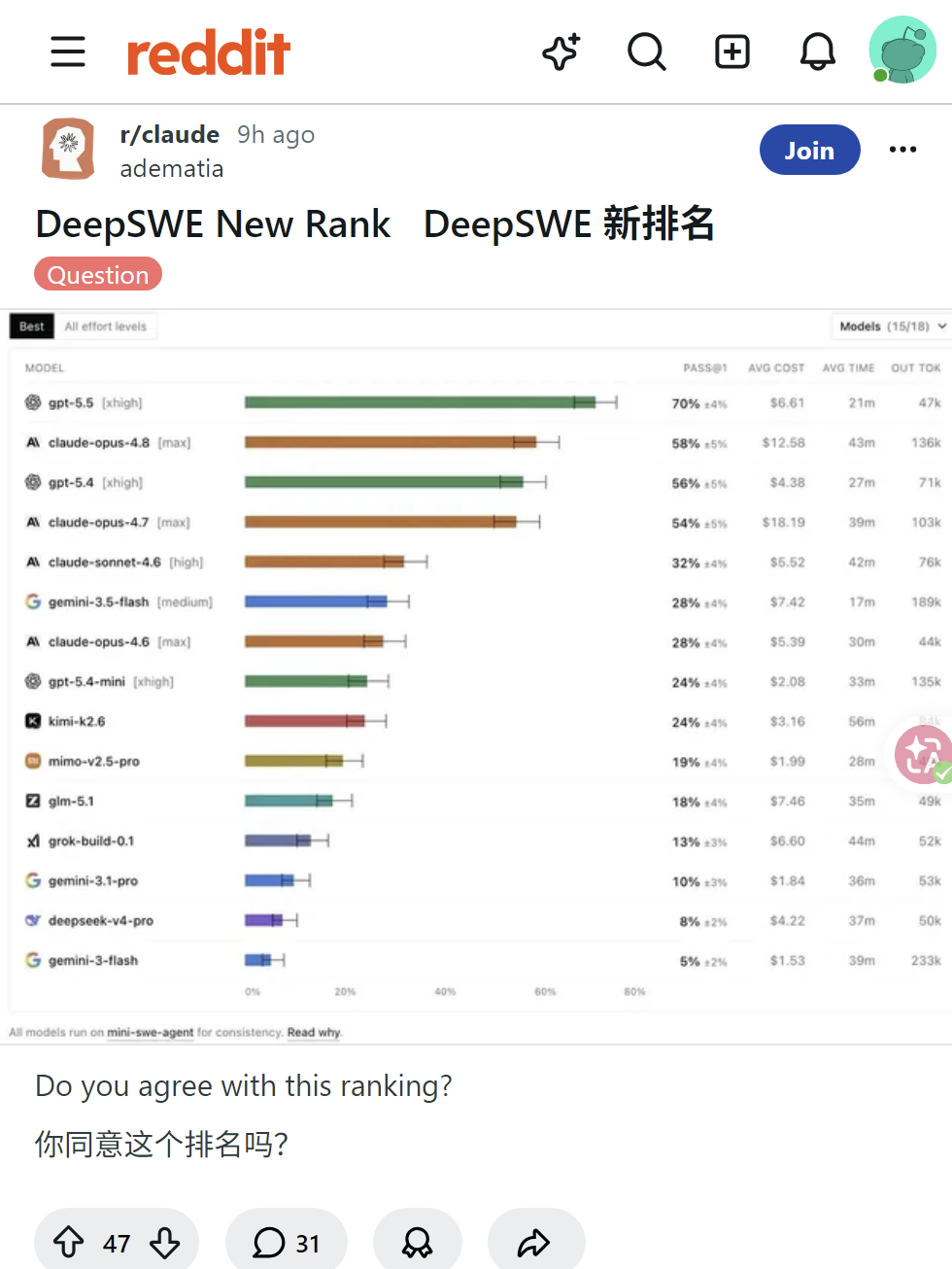
网友对DeepSWE基准测试争议不断,有人质疑其标准权威性,认为测试偏向特定提示风格;有人指出GPT 5.5虽通过测试但代码质量差,而Claude实际表现更好。多数用户认为基准测试无法衡量代码质量、可维护性等真实工作要素,建议根据自身需求选择模型。
0
0
 小陈
manage
advert
小陈
manage
advert
2026-06-01 03:00:22

回复 |
引用
小陈
manage
advert
2026-06-01 03:00:51

回复 |
引用
共2条
1
