Reddit热议!llama.cpp新PR省显存,网友狂赞贡献者
2026-05-30 11:05:01
1次阅读
3个评论
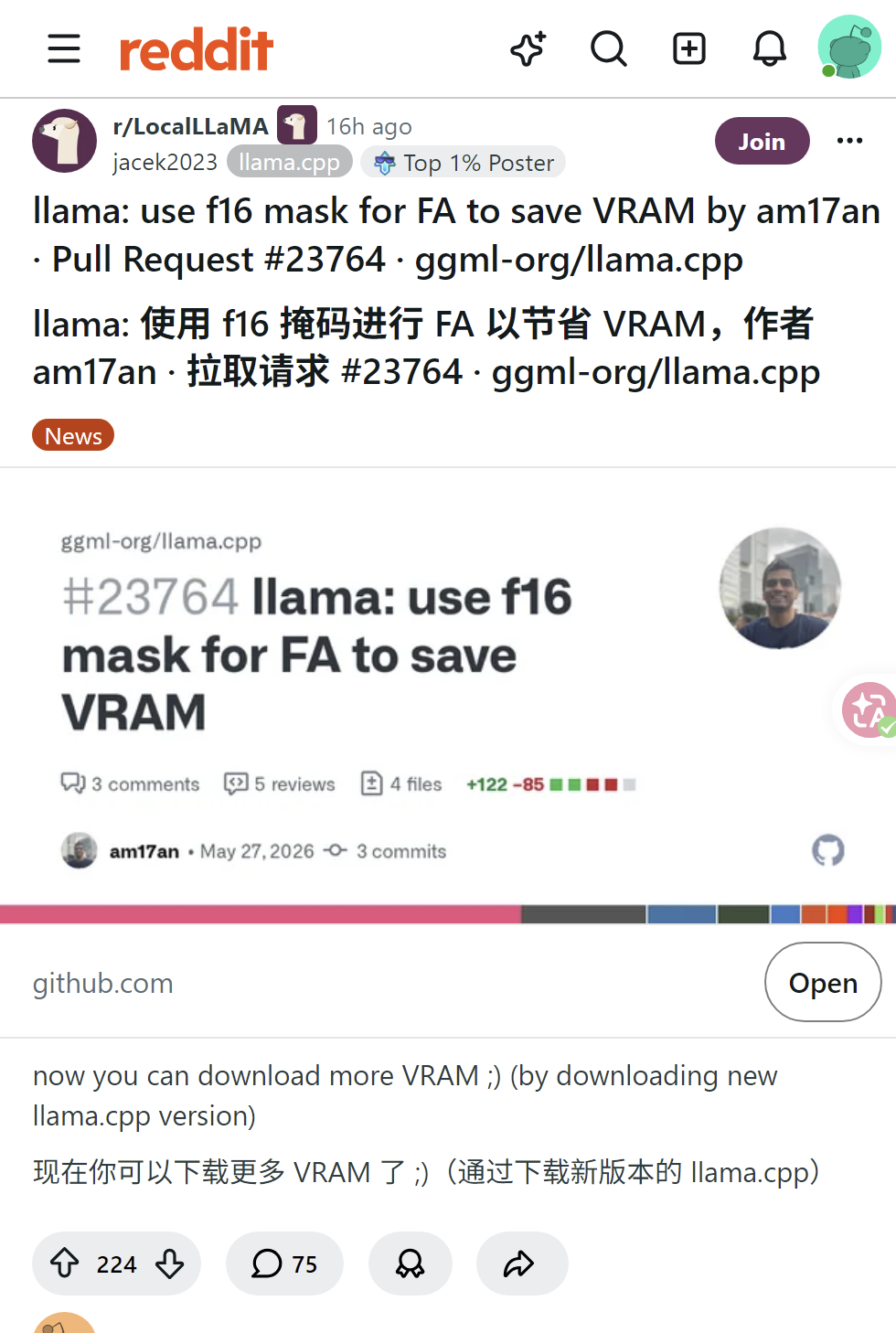
llama.cpp最新PR通过使用f16掩码优化FlashAttention,可节省高达1.2GB显存,尤其对MTP和大上下文模型效果显著。贡献者am17an获社区高度认可,被赞“年度贡献者”,网友期待未来能用8GB显存运行100B模型。
0
0
 小陈
manage
advert
小陈
manage
advert
2026-05-30 11:05:34

回复 |
引用
小陈
manage
advert
2026-05-30 11:06:02

回复 |
引用
小陈
manage
advert
2026-05-30 11:06:31

回复 |
引用
共3条
1
