Reddit热议!MTP正式合并入llama.cpp,网友实测性能飙升
2026-05-17 17:38:59
20次阅读
3个评论
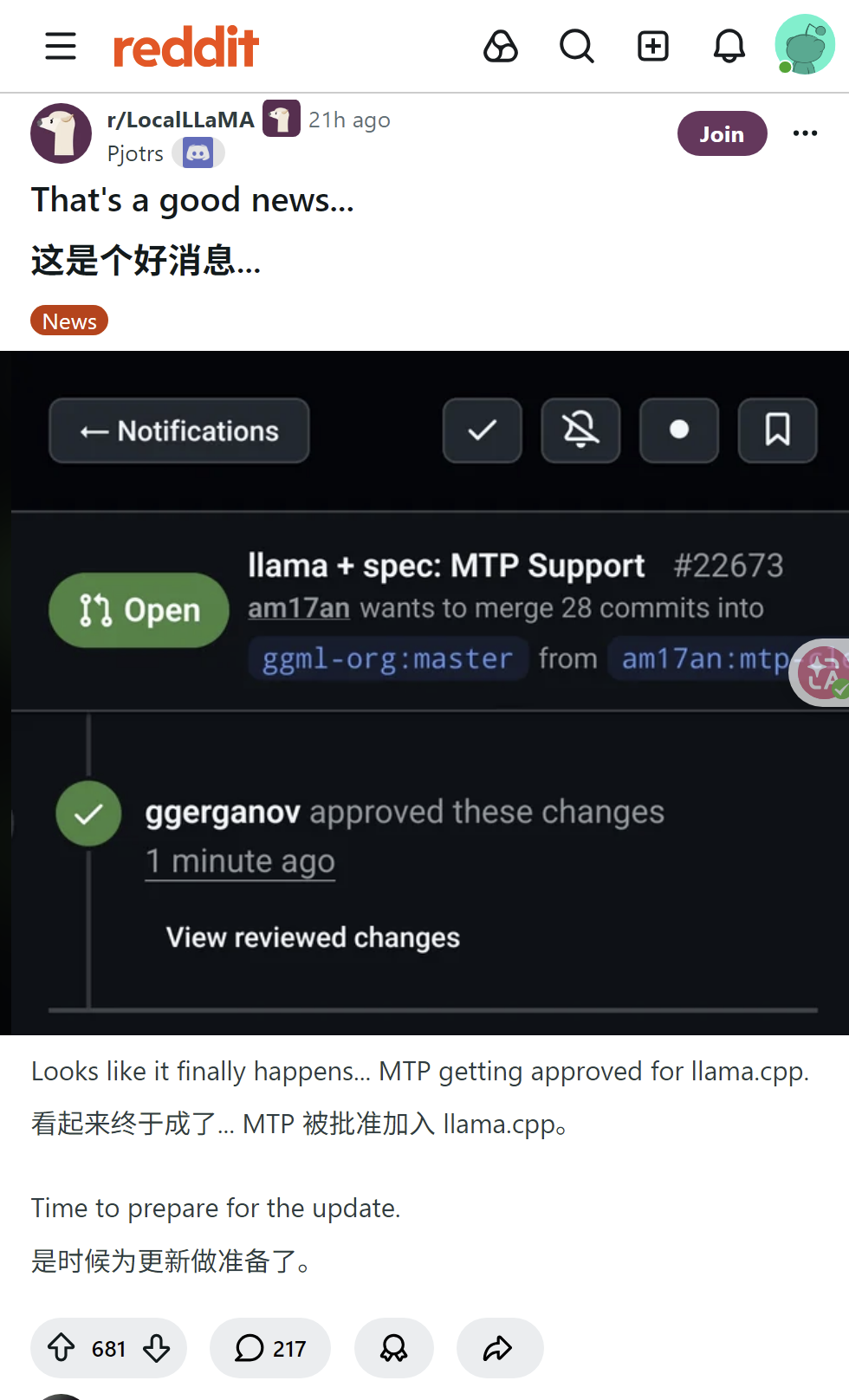
llama.cpp项目正式合并了MTP(Multi-Token Prediction)功能,支持Qwen等模型的多token并行预测。网友实测显示,在RTX 5090上可达105-110 tok/s,Strix Halo上从4-5 tok/s提升至12 tok/s,AMD 6700xt上从28提升至48 tok/s。但部分用户指出MTP会降低prompt处理速度、增加显存占用,且对MoE模型效果有限,更适合编程等低熵任务。
0
0
 小陈
manage
advert
小陈
manage
advert
2026-05-17 17:39:32

回复 |
引用
小陈
manage
advert
2026-05-17 17:40:01

回复 |
引用
小陈
manage
advert
2026-05-17 17:40:30

回复 |
引用
共3条
1
